时间与窗口的验证
1 | package flink.demo.time |
1 | package flink.demo.time; |
1 | package flink.demo.time |
1 |
|
时间与窗口的验证
1 | package flink.demo.time |
1 | package flink.demo.time; |
1 | package flink.demo.time |
1 |
|
保持与 Redis 相同的 TTL 操作
Redis 中没有 Hbase 中时间版本的概念与机制,也可以认为只有当前版本,并且 TTL 是针对整个 Key 的,而 Hbase 的 TTL 可以基于列族或者单元设定,不是基于整个行键的,如果我们将 Redis 中的数据迁移到 Hbase 中,对应的 TTL 就是一个问题,原来基于 Redis 机制的应用中使用也是一个问题,所以为了保持旧的应用兼容(在不对原有应用做大量重构测试的情况下,只在 API 层面兼容修改),只能手动针对 Hbase 的单元的 TTL 进行设置。
假设现在 API 层面,需要将原有的 Redis 访问替换为 Hbase 的访问,需要做一些 API 层面的映射。首先抛开所使用的底层缓存方案,将缓存抽象:每个缓存数据都属于一张表,这张表中缓存的是某个特定领域,特定应用的数据,访问时,需要指定表名,有两种基本的结构(和 Redis 保持一致) Key-Value, Key-HashKey-Value, 这样就可以为开发人员提供一个抽象层的 API, 开发人员并不需要特别关注底层缓存的方案,如果后面更换缓存方案,可以提供 API 层的兼容。
Hbase 中单元有时间版本的概念(VERSIONS), 一般设置 1 就够了,还有最小版本(MIN_VERSIONS), 可以设置为 0, 保证早于 TTL 的时间版本的数据不会返回。如果我们多次对一个单元进行写,即使设置了最大版本为 1, 如果最近的版本因为 TTL 过期,之前的版本没有过期,而且因为没有合并,没有被删除,还是会被查询出来,这显示对于原来使用 Redis 的应用来说,是不可接受的,所以只能在设置 TTL 时,手动删除之前的版本,而且, TTL 一般来说只是影响数据保存的时间长短,我们是为了清理数据设置的 TTL, 所以这个操作可以异步来进行。即使某次操作失败了,也可以等待下一次的操作进行设置。
这是一个同步的测试,使用 checkAndMutate 方法
1 | package test.bigdata |
内容取自 byte-of-vim, 查看原文,请参考文末链接.
Vim 是一个用于写作的计算机程序(computer program),提供一系列特性帮助你更好地进行写作。 可以用来编写购物清单,写书,或者是程序代码。
There is no great writing, only great rewriting.
——Louis Brandeis
与纯文本或富文本编辑器对比,Vim 可以使得复杂大量频繁的修改该变得更容易,更快,更好。Minimal effort. Maximal effect.
说了这么多漂亮话,Vim 到底强在哪里?
| 编辑 | Vim 中的操作 |
|---|---|
| 如何将光标向下移动 7 行 | Press 7j |
| 删除一个单词 | Press dw |
| 搜索文档中光标所在的单词 | Press * |
| 在 50-100 行进行查找并替换 | Run :50,100s/old/new/g (s = substitute, c = confirmation ) |
| 如果光标所在的单词是一个文件,如何打开 | gf (g = goto, f = file) |
| 如果每行只有前N个字符是有用的? | ctrl-v –> y (copy) |
| …… | …… |
所以,你被说服了吗?
我们为什么学习 Vim ?
Windows
Mac OS X
Linux/BSD
Windos 下的 Vim
Windows
Mac OS X
Linux/BSD
Vim 中的模式也许是最令刚接触 Vim 的人最疑惑的部分,为什么打开不能直接输入文字?该怎么样保存并退出 Vim?据说 Stack Overflow 上关于如何退出 Vim 的问题,其点击量已有上百万次了
Vim 中不同的模式就像是电视机中的正常模式和 DVD 模式,每种模式都有其特定的功能。模式使得功能区得以划分,使得事情变得尽可能简单。Vim 的目标之一就是使用键盘就可以完成所有工作,而不需要借助鼠标。
A mode for running commands
Vim 启动的默认模式
1 | # Vim command :echo |
A mode for writing text
打开 Vim,命令行模式下运行 :e temp.txt, 按下 i, 进入编辑模式,输入文本;
按下 <ESC>, 切换回命令行模式,运行 :w 命令保存
使用命令进行更方便的移动光标
除了 i 之外,你还可以
| Command | Action |
|---|---|
| i | insert text just before the cursor |
| I | insert text at the start of the line |
| a | append text just after the cursor |
| A | append text at the end of the line |
光标移动,并切换为 Insert Mode
其他常用操作命令
| Command | Action |
|---|---|
| o | open a new line below |
| O | open a new line above |
| s | substitute character |
| S | substitutes the whole line |
| r | replace the current character |
| R | replace continuous characters |
编辑完文本,切换回 Normal Mode, 是一个良好的习惯,完成文档的初始编写时,最好切换为 Normal Mode。
这两种模式的切换时如此的简单,按下 i 即可进入编辑模式, <ESC> 即可切换为命令行模式,图形化界面看似提供了很多菜单选项,可是如果上百个命令,以及这些命令的组合,图形化界面是难以做到的。
一旦你理解了 Vim 的模式 (哲学), 你就不会觉得好难用,好奇怪,是吧?
假如想要选中一连串的单词(words),并将它们完全替换为新的文本, 该如何做呢?你可不想按住删除键全部删除,再重新添加新的文本吧?Visual Mode 就将发挥它的作用。
Normal Mode 下,按下 v 或则 V 进入 Visual Mode
| Command | desc |
|---|---|
| v | Visual Mode, character basis |
| V | Visual Mode, line basis |
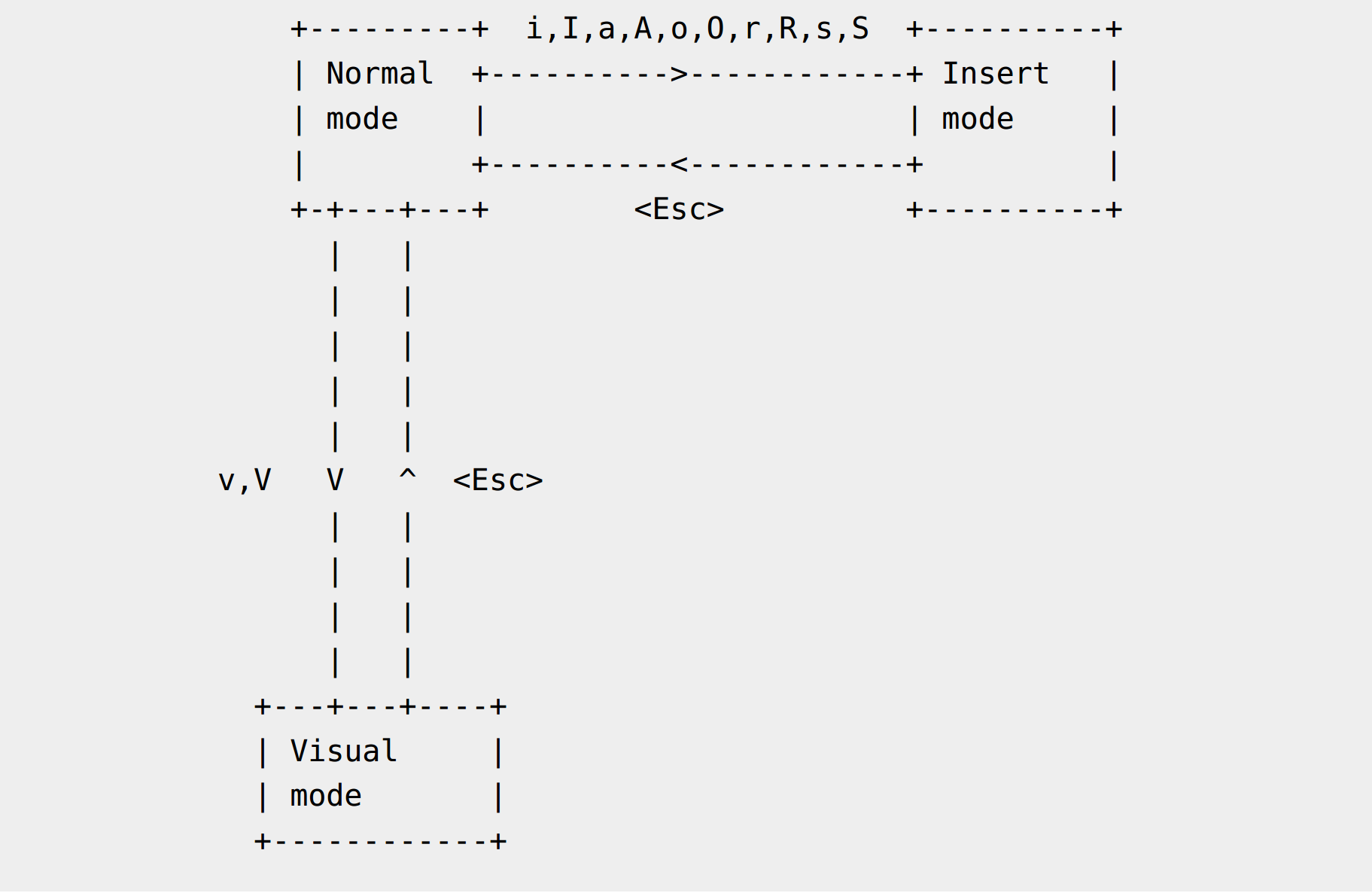
relation between the difference modes
理解模式是如何工作的,以及如何进行模式的切换是成为一个 Vimmer 的关键,当然, Vim 也只是众多编辑器中的一种 (如 Vim 于 Emacs 之争),如何选择,取决于你的个人习惯和偏好,工欲善其事必先利其器,Vim 也只是提供了一种选择,这个看似古老的软件依然在庞大的程序员群体中占有一席之地,继续发光发热。
[1] A Byte of Vim
[2] 7 versatile Vim commands that are easy to memorize
[3] Vim Galore
req_params 文件中每一行都是一个 JSON 字符串,表示每次请求的请求体
1 | {"a":"b", "c":"{\"d\":\"f\"}"} |
现在需要针对每个请求体进行调用
1 | # 重点在于 read 的参数 -r, 表示 raw 模式,不把输入的反斜杠字符解释为转义字符 |
使用 here document 进行请求参数的填充
1 | while read ph; do |
xxd 用来对指定的文件或来自标准输入的数据进行十六进制转储,也可以将将十六进制转换为原始的二进制格式,允许以邮件安全的 ASCII 表示传输二进制数据,base64 其实也可以达到相同的目的。也可以用来进行二进制文件 patching
如果没有指定输入文件或输出文件,或者指定为 - ,使用标准输入或标准输出
-a | -autoskip 开启自动跳过,以 * 代替空行(nul-lines),默认关闭
-b | -bits 切换到二进制位模式,而不是十六进制, -r, -p,-i 下不生效
1 | $ echo -n "hello" | xxd -b |
-c cols | -cols cols 输出的每行包含 cols 个字节,默认是 16 个 (-i: 12, -ps: 30, -b: 6).最大 2561 | $ echo -n "hello" | xxd -b -c 2 |
-E | -EBCDIC ASCII 表示切换为 EBCDIC(国际)编码 meaningless in combinations with -r, -p or -i
-g bytes | -groupsize bytes 每 bytes 个字节,添加一个空格进行分隔分组
1 | $ echo "hello" | xxd -g 1 |
-p | -ps | -postscript | -plain 以连续连续十六进制样式输出1 | $ echo "hello" | xxd -p |
-r | -revert 将十六进制转为二进制。如果不是写到 stdout, xxd 在不截断的情况下将其写入输出文件。使用 -r -p 读取连续的十六进制输出(不包含行号信息,没有特定的列布局)
-seek offset
When used after -r: revert with <offset> added to file positions found in hexdump.
-s [+][-]seek
start at <seek> bytes abs. (or rel.) infile offset. + indicates that the seek is relative to the current stdin file position (meaningless when not reading from stdin). - indicates that the seek should be that many characters from the end of the input (or if combined with +: before the current stdin file position). Without -s option, xxd starts at the current file position.
跳过多少字节
1 | xxd text |
-l len | -len len 只打印出 len 个字节1 | xxd -l 5 text |
-u 使用大写的十六进制字母,默认是小写的
1 | # Create a 65537 byte file with all bytes 0x00, except for the last one which is 'A' (hex 0x41). |