并行流 MapCollect 模型
Java 8 中引入了流 Stream,并通过流极大的简化了集合以及I/O ( 见 Files 类) 的操作,和 Spark 中对 RDD 的各种操作是类似的。并且通过 ForkJoin 框架实现了并行流 (基于分治的思想),如果和 Spark RDD 相比,都给开发者提供了将任务并行化的便利,RDD 中的每个 Partition 对应一个 Task,由 Spark 中的执行器分别执行,Java 中的并行流拆分后的每一个 Spliterator (可拆分迭代器)也是一个任务,由 ForkJoin 公用池中的工作线程执行,而且 Stream 与 RDD 都有类似的中间操作和终端操作,异曲同工啊。并且都为开发者提供了易于使用的接口或者说数据结构。
MapCollect 模型 (见 《精通 Java 并发编程》)也就是使用流来收集数据,将最终的结果收集在一个容器中,而不是约简为(reduce)为一个值,对应 java.util.stream.Stream#collect(java.util.stream.Collector<? super T,A,R>) 方法, 需要提供一个收集器 Collector 对象。
JDK 中 Collector 接口中有这样一段话:
For concurrent collectors, an implementation is free to (but not required to) implement reduction concurrently. A concurrent reduction is one where the accumulator function is called concurrently from multiple threads, using the same concurrently-modifiable result container, rather than keeping the result isolated during accumulation. A concurrent reduction should only be applied if the collector has the
Collector.Characteristics.UNORDEREDcharacteristics or if the originating data is unordered.
对于并发收集器 concurrent collectors 的实现, 可以自由实现并发规约. 并发规约 concurrent reduction 指的是的 accumulator 函数可以被多个线程并发调用, 且使用同一个支持并发修改的结果容器 (支持并发修改, 普通的 ArrayList 显然不支持并发修改), 而不是在累加函数执行过程中保持独立的结果容器 (即每个拆分后的任务拥有一个结果容器). 并发规约只有该收集器指定 UNORDERED 特征 (即不关心元素被处理的顺序),或者背后的数据源本身是无序的才可以应用该优化 (当然,也要指定 CONCURRENT 特征).
收集器的 UNORDERED 特征与无序的 Stream 指的同一件事情,即不要求按照流中的元素的顺序来依次处理,这在并行流的某些终端操作下,无疑可以提升性能。
流的串行执行过程
首先是串行实现过程, 对一个数字流进行转换并收集到一个 List 中:
1 | List<String> collectResult = IntStream.rangeClosed(1, 20) |
控制台打印的结果:
1 | Thread[main,5,main] create supplier |
串行只有一个线程 (主线程) 来执行规约过程, 调用 supplier 函数创建结果容器(累加器), 执行 accumulate 累加过程 (将流中的元素添加到结果容器中), 并且由于中间结果容器就是最终想要的结果, 而且是串行的, 不需要执行 combine 和 finish 函数
流的并行执行过程
通过 parallel 方法将流转换为并行流, 其它不变
1 | List<String> collectResult = IntStream.rangeClosed(1, 20) |
控制台打印的结果:
1 | Thread[main,5,main] create supplier |
可见中间穿插着多次创建中间结果容器 (打印 create supplier), 也多次调用了 combine 函数对中间容器的结果进行合并, 复合预期, 也就是通过 ForkJoin 框架对数据进行递归划分, 每个划分创建自己的结果容器, 针对该划分内的元素进行累加过程, 最终将所有划分的结果进行合并得到最终的结果.
并发规约
接下来, 指定收集器的特征为 Collector.Characteristics.CONCURRENT, Collector.Characteristics.UNORDERED 以实现并发规约过程, 并且使用了线程安全的 CopyOnWriteArrayList 作为结果容器, 支持并发修改
1 | List<String> collectResult = IntStream.rangeClosed(1, 20) |
控制台打印结果:
1 | Thread[main,5,main] create supplier |
可以看出, 只创建了一个中间结果容器对象, 所有的线程调用累加函数的时候, 都使用该容器. 并将最终的结果返回.
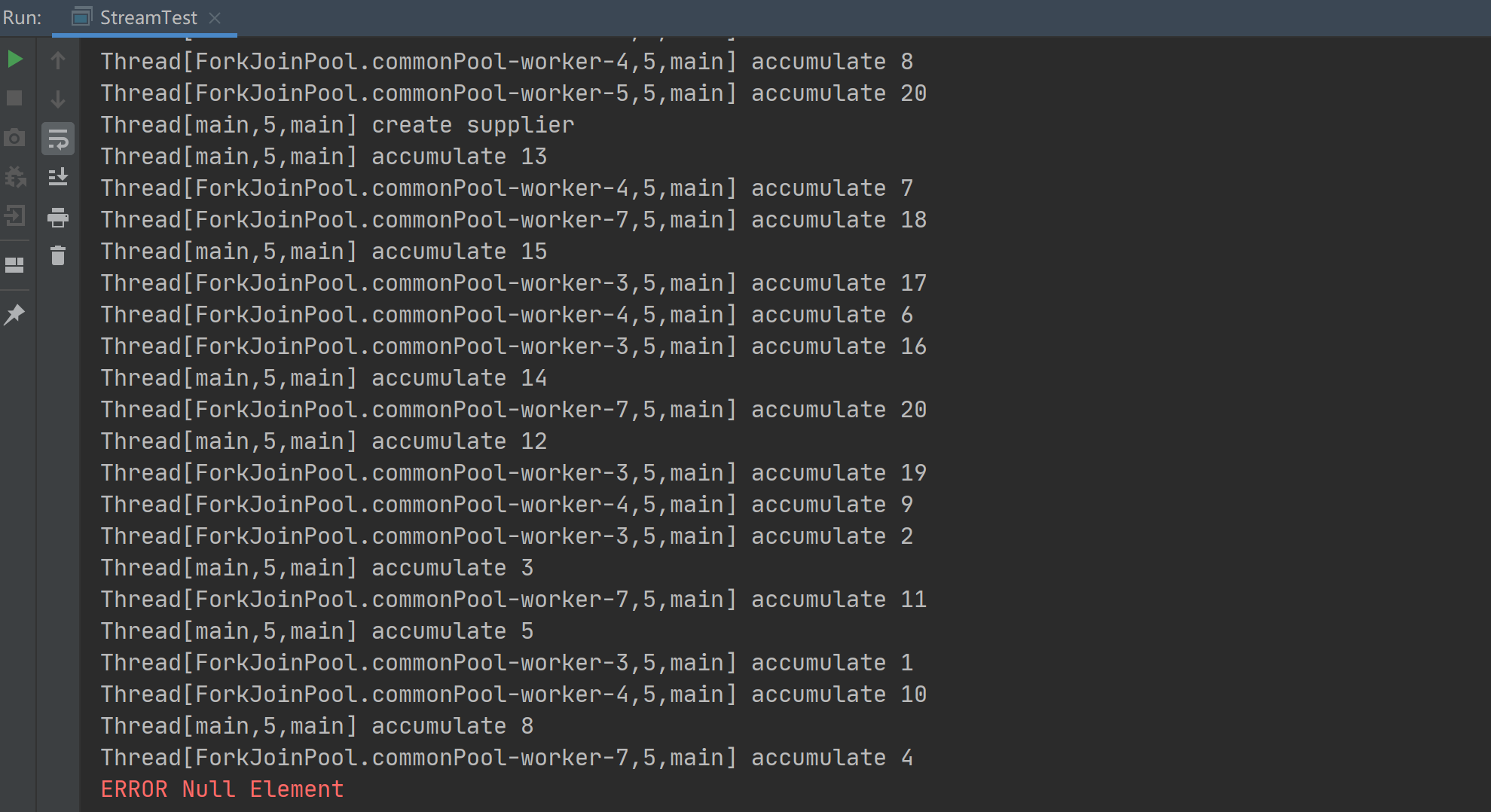
如果使用线程不安全的 ArrayList, 如下所示, 为了验证最终结果的错误, 循环执行, 直到某次执行因为并发修改引起异常或结果中出现 Null 元素终止:
1 | while (true) { |
执行结果:
由于并行规约会创建一个中间结果容器, 并在多个线程的累加函数中使用, 此处使用的是非线程安全的 ArrayList, 因此在执行过程中会出现异常或 Null 元素而退出
是否要使用并行化流
并行流是否能提升性能, 需要综合考虑, 不一定就比串行流的执行效率高, 比如数据量较小, ForkJoin 的递归划分和合并总归是有性能消耗的. 这其实和是否要对某个任务进行并行化, 怎样进行并行化要做的考虑是类似的. 见 《Java 实战 (第2版)》第 7 章 的 正确使用并行流 和 高效使用并行流
参考阅读
[1] 精通 Java 并发编程
[2] Java 实战