问题还原
表结构及索引情况
1 | > desc user_info |
表的大小和 user_score 表的数据
1 | select count(*) from user_info |
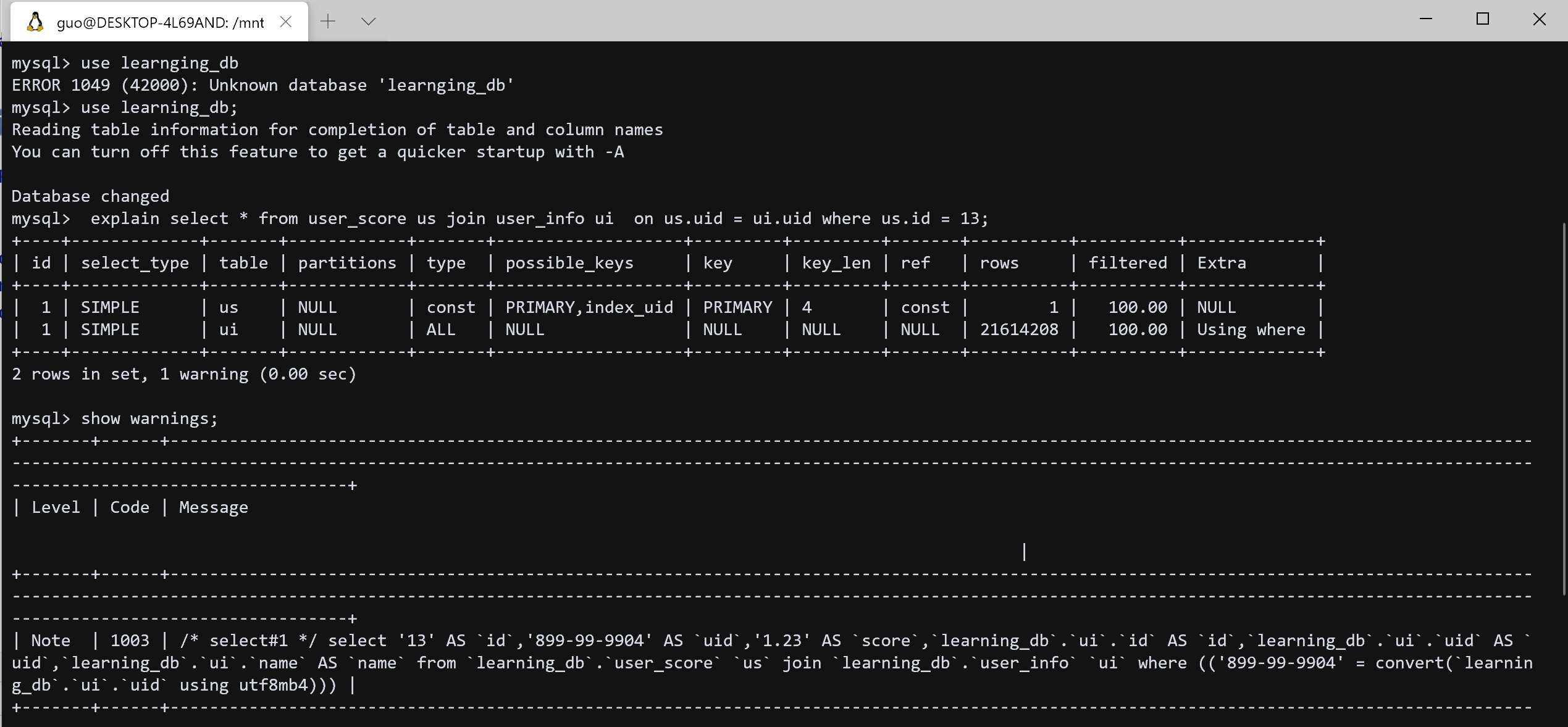
1 | select * from user_score us join user_info ui on us.uid = ui.uid where us.id = 13; |
执行计划
1 | id select_type table partitions type possible_keys key key_len ref rows filtered Extra |
1 | show create table user_info; |
1 |
|
字符集不一致的问题导致索引失效.
修改字符集:
1 | ALTER TABLE user_score CONVERT TO CHARACTER SET utf8; |
1 | select * from user_score us join user_info ui on us.uid = ui.uid where us.id = 13 |
执行计划:
1 | id select_type table partitions type possible_keys key key_len ref rows filtered Extra |
- 如果存在 JOIN 连接等操作的表,在建表的时候就应该留心之前系统的规范是什么,建表的默认字符集或者规定的字符集是什么, 而不应该依靠于自己的喜好和认知去建立
- 索引列参加计算会导致索引失效,所以非索引常量等值条件的查询,或者较复杂涉及连接的查询,都应该提前分析是否会使用索引,语句的效率,测试执行时间,查看执行计划,看看是否符合预期
原文地址: https://mp.weixin.qq.com/s/Cimeyo4cVQsF-MfHBsNgGg?1=a
1 | explain select * from user_info ui straight_join user_score us on ui.uid = us.uid where us.id = 13 |
1 | [HY000][1003] /* select#1 */ select `learning_db`.`ui`.`id` AS `id`,`learning_db`.`ui`.`uid` AS `uid`,`learning_db`.`ui`.`name` AS `name`,`learning_db`.`ui`.`upd_time` AS `upd_time`,`learning_db`.`us`.`id` AS `id`,`learning_db`.`us`.`uid` AS `uid`,`learning_db`.`us`.`score` AS `score` from `learning_db`.`user_info` `ui` straight_join `learning_db`.`user_score` `us` where ((`learning_db`.`us`.`id` = 13) and (`learning_db`.`us`.`uid` = convert(`learning_db`.`ui`.`uid` using utf8mb4))) |
在字符集编码相同的情况下,强制使得 user_info 表作为驱动表的情况:
1 | explain select * from user_info ui straight_join user_score us on ui.uid = us.uid where us.id = 13; |
外连接
备注:使用的 Mysql版本为 5.7 ,参考的Mysql官方使用手册也是 5.7 的
1 | : 5.7.29-0ubuntu0.18.04.1 |
外连接 Outer Joins 包含 LEFT JOIN 和 RIGHT JOIN
在外连接 A LEFT JOIN B 中将 B 表的筛选条件写在连接条件 (JOIN CONDITION, on A.col = B.col)和写在 WHERE 字句中的结果
此例中,user_info_temp 表中有一条 uid 为 '899-99-9905' 的行,user_score_temp 中有两条 uid 为 '899-99-9905' 的数据
B 表的筛选条件写在连接条件中
sql 语句:
1 | select * from user_info_temp ui left join user_score_temp us on us.uid = ui.uid and us.uid = '899-99-9905'; |
执行计划:
1 | id select_type table partitions type possible_keys key key_len ref rows filtered Extra |
执行结果:
1 | id uid name id uid score |
B 表的筛选条件写在 WHERE 字句中
sql 语句:
1 | select * from user_info_temp ui left join user_score_temp us on us.uid = ui.uid where us.uid = '899-99-9905'; |
执行计划:
1 | id select_type table partitions type possible_keys key key_len ref rows filtered Extra |
执行结果:
1 | id uid name id uid score |
解释
出现不同结果的原因是,写在连接条件中,会作为连接前筛选 B 表的条件,B 表中满足条件的有两条, 再做外连接; 而写在 WHERE 字句中,是作为连接后的结果的筛选条件的, 只筛选出结果中 B 表的列满足条件的结果.
Mysql 手册 - 8.2.1.8 Outer Join Optimization 节中对外连接的步骤有如下描述:
The LEFT JOIN condition is used to decide how to retrieve rows from table B. (In other words, any
condition in the WHERE clause is not used.)
也就是说, 连接条件决定了如何从 B 表中进行检索数据, WHERE 子句中 B 的条件此时是不会使用的.
还需要注意一点的是, B 表的筛选条件写在 WHERE 字句中, 此时, Mysql 应该是将其转换为一个 INNER JOIN 了, 执行计划中的两个步骤都是用的索引, 而且在控制台中对应打印出了如下的结果:
1 | [HY000][1003] /* select#1 */ select `learning_db`.`ui`.`id` AS `id`,`learning_db`.`ui`.`uid` AS `uid`,`learning_db`.`ui`.`name` AS `name`,`learning_db`.`us`.`id` AS `id`,`learning_db`.`us`.`uid` AS `uid`,`learning_db`.`us`.`score` AS `score` from `learning_db`.`user_info_temp` `ui` join `learning_db`.`user_score_temp` `us` where ((`learning_db`.`us`.`uid` = `learning_db`.`ui`.`uid`) and (`learning_db`.`ui`.`uid` = '899-99-9905')) |
其中并没有出现 left join , 而是被转换成了 join, 大概想下, 这时的外连接其实是等价于内连接的, 如果 B 的常量等值条件要满足, B 表对应的那一行必然和 A 表中的某一行关联的上, 不能关联上, 则都为 NULL (前提是 B 的条件列声明为 NOT NULL), 所以是等价于内连接的.
因此, 在这种情况下, 写成内连接更能表达清楚本来的意图.
Mysql 手册 - 8.2.1.8 Outer Join Optimization 中的相关描述:
For a LEFT JOIN, if the WHERE condition is always false for the generated NULL row, the LEFT JOIN
is changed to an inner join.
如果 t2.column 为 null, t2.column2=5 这个条件总是 false
1 | SELECT * FROM t1 LEFT JOIN t2 ON (column1) WHERE t2.column2=5; |
因此,可以安全的等价为一个内连接:
1 | SELECT * FROM t1, t2 WHERE t2.column2=5 AND t1.column1=t2.column1; |
在进行转换后,查询优化器(optimizer)就可以根据情况,做出一个较优的查询计划,比如,使用 t2 作为驱动表
不能进行转换的情况
所以如果 B 的条件列可以是 NULL (没有声明为 NOT NUll), 而且条件为 B.col is NULL , 这时, 就不能等价于内连接了, 因为满足 B.col is NULL 的情况有两种, 一种是本来就没有关联上, 另一种是关联上了, 这一列的值本来就是 NULL, 就不满足 WHERE condition is always false for the generated NULL row
外连接的简化
- 解析阶段,右连接会被转换为只包含左连接
1 | (T1, ...) RIGHT JOIN (T2, ...) ON P(T1, ..., T2, ...) |
1 | (T2, ...) LEFT JOIN (T1, ...) ON P(T1, ..., T2, ...) |
1 | select * from user_info_temp a right join user_score_temp b on a.uid = b.uid; |
1 | mysql> show warnings; |
- 所有
T1 INNER JOIN T2 ON P(T1, T2)形式的内连接表达式,会被替换成,T1,T2,P(T1, T2)会作为WHERE条件进行结合
1 | select * from user_info_temp a join user_score_temp b on a.uid = b.uid; |
1 | mysql> show warnings; |
- 利用外连接的转换,获得更优的执行计划
1 | SELECT * T1 LEFT JOIN T2 ON P1(T1,T2) |
如果此时 R(2) 这个限制条件能够极大的减少 T2 表中匹配的行数,但是还时按照当前的执行顺序,先访问 T1, 再访问 T2 表,就可能会产生一个不够高效的执行计划
如果此时,能够将这个外连接转换为内连接,可能会有一个更高效的执行计划。
什么样的情况下,一个外连接可以被转换为一个内连接?
MySQL converts the query to a query with no outer join operation if the WHERE condition is null-rejected.
A condition is said to be null-rejected for an outer join operation if it evaluates to FALSE or UNKNOWN for any NULL-complemented row
generated for the operation.如果对于外连接操作的补足NULL行(A LEFT JOIN B –> B.COL IS ALL NULL), 这些条件总是
FALSE或者UNKNOW的,这些条件就是null-rejected的
考虑这样一个简单的外连接:
1 | T1 LEFT JOIN T2 ON T1.A=T2.A |
通用的检查规则
A IS NOT NULLA 是左连接内表的一个属性一个谓词(predicate)条件,其中包含了对左连接内表的引用,并且当这个谓词的某一个参数为 NULL 时,谓词返回的值为
UNKNOWN什么是谓词?谓词就是返回值为真值(
TRUE, )的函数,如= < > <>比较谓词,LIKE谓词,BETWEEN谓词,IS NULL, IS NOT NULL,IN谓词,EXISTSAND 进行连接条件,包含了一个 null-rejected 的条件
OR 连接的条件,并且所有条件都是 null-rejected
示例*
- 简单转换
1 |
|
- 连续触发
1 | -- before converted |
MySQL Optimizer 查询优化器
会根据当前表的信息给出执行计划,所以类似的查询语句可能在不同的情况下执行计划不同:
user_info 表和 user_score 两张表, user_info 表有 2200 百万数据,表 user_score 有 6 条数据,通过 uid 字段可以关联,且两张表的 uid 字段都设置了索引:
1 | select count(*) from user_info |
- 当连接的筛选条件为
uid = '899-99-9904'时,user_score 表中有两条可以关联的上,执行计划:
1 | explain select * from user_info ui join user_score us on us.uid = ui.uid where ui.uid = '899-99-9904'; |
可以看出,此时给出的执行计划, 驱动表 ui, 被驱动表 us 都是索引查询,使用的应该是 Indexed Nested Loop Join 连接算法。
- 当连接的筛选条件为
uid = '899-99-9905'时,user_score 表中有四条可以关联的上,执行计划:
1 | explain select * from user_info ui join user_score us on us.uid = ui.uid where ui.uid = '899-99-9905'; |
此时的执行计划, 连接算法使用的时 Block Nested Loop Join 连接算法 (参考 Mysql 使用手册 - 8.2.1.6 Nested-Loop Join Algorithms),且 user_info 使用了索引;这时,会扫描 user_score 表一次,将 user_score 表中的每一条记录同 Join Buffer 连接缓冲区中的 user_info 表筛选出来的记录进行匹配,如果满足关联条件,返回。
猜想:此时,查询优化器可能是从 uid 的索引的情况来看,user_score 表中 uid = '899-99-9905' 的记录占据了整个表的大部分,而且表本身比较小,此时,做一次全表扫描的性能可能是会更好。
Mysql 查询优化器的工作是一个很复杂的工作流程、会考虑各种因素,参考表的统计信息,给出当前较优的执行计划。
Using filesort (JSON property: using_filesort)
MySQL must do an extra pass to find out how to retrieve the rows in sorted order. The sort is done
by going through all rows according to the join type and storing the sort key and pointer to the row for
all rows that match the WHERE clause. The keys then are sorted and the rows are retrieved in sorted
order. See Section 8.2.1.14, “ORDER BY Optimization”.