PKCS
PKCS (Public-Key Cryptography Standards) 公钥密码标准由 RSA 公司制定, 用于标准化公钥基础设施 (public key infrastructure), 从 PKCS #1, PKCS #2 到 PKCS #15 总共提供了 15 个标准
PKCS #1
RSA 密码算法的加密标准,定义了 RSA 公钥函数,数字证书等的基础规则;也定义了 RSA 私钥和公钥的语法, 可以用来计算 RSA 算法中使用的密钥对。除了这些,还定义了数字证书应该如何计算,以及数据的结构应该如何被签名,数字签名的格式
用于 RSA 公钥密钥
PKCS #7
加密消息语法标准。定义了加密操作结果形式数据的语法,例如数字签名 (digital signature) 和数字信封 (digital envelopes)
用于生成和验证数字签名和由 PKI 管理的证书
用于证书或证书链
示例
生成 PKCS 7 证书链
1 | # ca.p7b created through openssl crl2pkcs7 command represents a certificate chain/path: |
使用 JCA 验证
1 | public static void loadCertPath() throws Exception { |
PKCS #8
私钥信息标准。定义了私钥信息的语法。换句话说,定义了用来生成私钥的算法以及属性
用于各种公钥密码
PKCS #12
该标准描述了用于个人身份信息传输的语法,包含私钥、证书,各种各样的密钥以及扩展等。支持该标准的机器、应用、浏览器等允许用户对个人身份信息进行导入、导出以及使用。这个标准允许用户使用标准机制将数据从一个设备传输到另一台设备,并且保证私密性和完整性(privacy and integrity), 可以使用受信任的公私钥对进行加密和签名,也可以使用基于口令的私密和完整性模式。
通过包含基本但辅助的身份信息以及私钥,以及通过公钥密码实现的隐私和完整性模式建立更高的安全性,可以将该标准视为在 PKCS#8 的基础上构建。
私密性主要是用于保护个人身份信息,如避免私钥(private key)泄露,有两种方式:
公钥密码模式 (Public-key privacy mode)
在信息交换前,个人身份信息通过使用来自受信任的目标平台的公钥(TPDestEncK)进行加密(envelop 封装于信封),加密后的数据只有目标平台持有的私钥才能进行解密(open envelop 开启信封)
1 | Public-key privacy mode: Personal information is enveloped on the |
基于口令的加密 (Password privacy mode)
从一个用户名以及私密口令生成一个对称密钥,用来进行加密个人信息
完整性主要用于确保内容没有被篡改,也有两种方式:
公钥密码模式 (Public-key privacy mode)
使用源平台的私钥对内容进行数字签名, 目标平台使用对应的公钥(TPSrcSigK)进行验证签名
基于口令的完整性 (Password privacy mode)
基于 MAC 消息验证码来保证,口令的目的是用于生成 MAC 中进行操作的共享密钥 (PBE,口令-盐-迭代次数)
私密性和完整性如果都使用基于口令的模式,他们可以使用相同的口令,也可以使用不同的口令
对于公钥/私钥对的两种使用,必须将密钥对中的公钥传输到另一个平台,以便可以信任它起源于正确的平台。 从这个意义上来说,判断公钥是否受信任最终必须留给用户。 有多种方法可确保公钥受信任(如公钥证书)。
PDU: 构成一个协议的消息的二进制位序列
Protocol Data Unit (PDU): A sequence of bits in machine-independent
format constituting a message in a protocol.
PFX: The top-level exchange PDU defined in this standard. The acronym is sometimes expanded as Personal Information Exchange.
用于数字证书+私钥, 常用文件后缀 .pfx, .p12 ,.pem
ASN.1 定义
1 | PFX ::= SEQUENCE { |
authSafe 的 content 字段包含了一个 AuthenticatedSafe 类型数据的 BER 编码(直接或间接(签名数据)), AuthenticatedSafe 类型可以包含多个 ContentInfo 类型的数据,其中的每一个 ContentInfo 的 content 的值要么是明文,要么是加密过的,要么是信封数据。如果是加密和信封数据,保存的是一个 SafeContents 实例的 BER 编码
1 | -- encrypted-data content type |
简单的图示
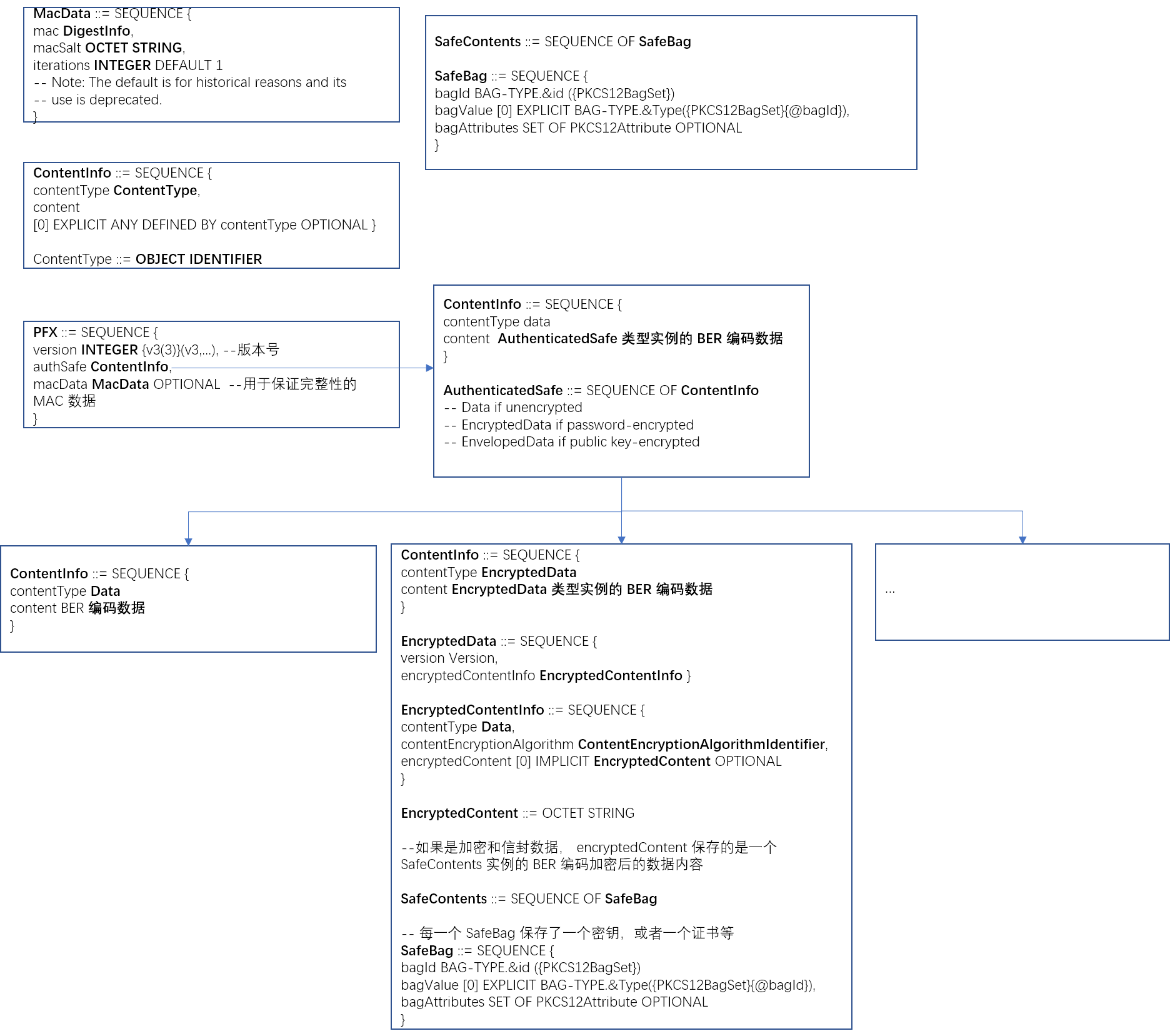
示例
1 | # 使用 openssl 创建 pkcs#12 文件 |
使用 openssl 的 asn1parse 命令来解析生成的 pkcs12 文件
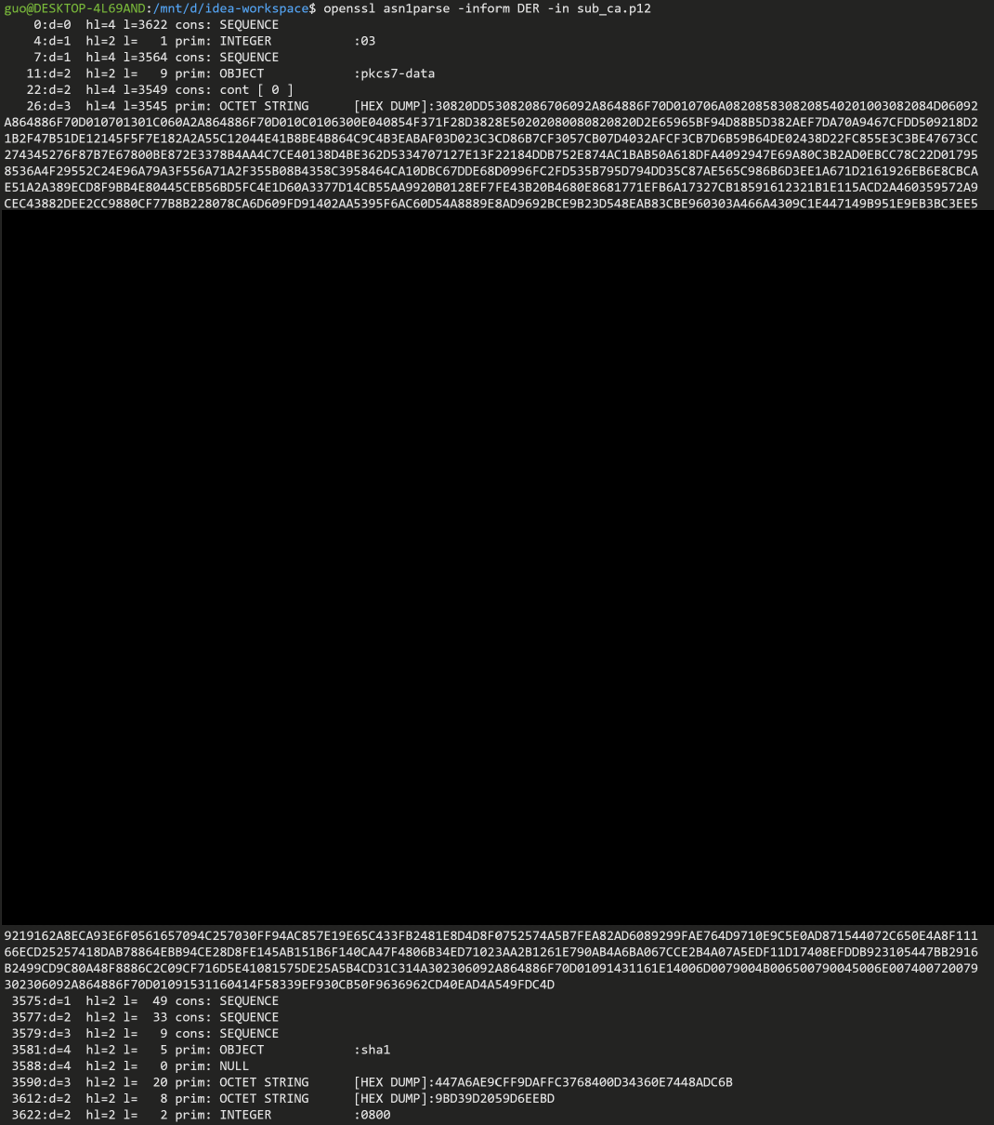
最后几行是 MAC 包含的信息,0800 表示 迭代次数, 倒数第二行是盐(salt)
PEM
PEM (Privacy Enhanced Mail) 私密增强邮件, 是 X.509 证书,CSRs (Certiticate Signing Requests) 证书签名请求,加密密钥的常用格式。PEM 文件包含了一个或多个 Base64 编码的内容,并且每一内容都有一个头部和尾部:
1 | -----BEGIN RSA PRIVATE KEY----- |
单个 PEM 文件可以包含一个证书,一个私钥,或多个证书组成完整的证书信任链。
通常使用的文件扩展名:.crt, .pem, .cer, .key (用于密钥)
参考文献
[1] PKCS
[2] PKCS #1
[3] PKCS #7
[4] PKCS #12