Automatic initialization and updating to the current date and time can be specified using DEFAULT CURRENT_TIMESTAMP and ON UPDATE CURRENT_TIMESTAMP column definition clauses. By default, the first TIMESTAMP column has these properties, as previously noted. However, any TIMESTAMP column in a table can be defined to have these properties.
MySQL converts TIMESTAMP values from the current time zone to UTC for storage, and back from UTC to the current time zone for retrieval. (This does not occur for other types such as DATETIME) By default, the current time zone for each connection is the server’s time. The time zone can be set on a per-connection basis. As long as the time zone settings remains constant, you get back the same value you store. If you store a TIMESTAM value, and then change the time zone and retrieve the value, the value is different from the value you stored. The current time zone is avaliable as the value of the time_zone system variable. This occurs because the same time zone was not used for conversion in both directions. The current time zone is available as the value of the time_zone system variable. For more information, see Section 5.1.13, “MySQL Server Time Zone Support”.
MySQL Server Time Zone Support
system time zone 系统时区,server 启动时,尝试自动获取所在机器的时区,并设置为 system_time_zone 系统变量(system variable)
要显示指定 Mysql Server 启动时的系统时区,启动 mysqld 服务前,设置 TZ 环境变量。 如果使用 mysqld_safe, 使用 --timezone 选项也可以设置
server time zone 服务器当前时区, 全局 time_zone系统变量表明了 server 当前操作使用的时区. time_zone 的初始化值是 SYSTEM, 表示和系统时区 (system time zone) 相同; 初始的全局 server time zone 也可以通过命令行选项 --default-time-zone 来设置,或者在 option 文件中指定 default-time-zone='timezone'; 如果拥有权限,也可以在运行时设置:
1
SETGLOBALtime_zone = timezone;
per-session time zone 针对每个会话的时区,每一个连接的客户端都有自己的会话时区设置,通过会话范围内的 time_zone 变量来设置;默认会话变量会从全局 time_zone 变量继承,但是客户端也可以修改:
1
SETtime_zone = timezone;
会话时区设置会影响与时区相关(zone-sensitive)的数据类型的展示和存储. 包含 NOW() 或者 CURTIME 函数值的展示,以及 TIMESTAMP 列的值的存储和查询. 存储时,TIMESTAMP 列的值会从当前会话时区转为 UTC 进行存储,查询时,再从 UTC 时间转为当前会话的时区时间
UTC_TIMESTAMP 函数和 DATE, TIME 或者 DATETIME 列的值不受会话时区影响,它们也不是转为 UTC 存储
/** * Configures the client's timezone if required. * * @throws SQLException * if the timezone the server is configured to use can't be * mapped to a Java timezone. */ privatevoidconfigureTimezone()throws SQLException { String configuredTimeZoneOnServer = this.serverVariables.get("timezone");
if (configuredTimeZoneOnServer == null) { configuredTimeZoneOnServer = this.serverVariables.get("time_zone");
if ("SYSTEM".equalsIgnoreCase(configuredTimeZoneOnServer)) { configuredTimeZoneOnServer = this.serverVariables.get("system_time_zone"); } }
String canonicalTimezone = getServerTimezone();
if ((getUseTimezone() || !getUseLegacyDatetimeCode()) && configuredTimeZoneOnServer != null) { // user can override this with driver properties, so don't detect if that's the case if (canonicalTimezone == null || StringUtils.isEmptyOrWhitespaceOnly(canonicalTimezone)) { try { canonicalTimezone = TimeUtil.getCanonicalTimezone(configuredTimeZoneOnServer, getExceptionInterceptor()); } catch (IllegalArgumentException iae) { throw SQLError.createSQLException(iae.getMessage(), SQLError.SQL_STATE_GENERAL_ERROR, getExceptionInterceptor()); } } }
// // The Calendar class has the behavior of mapping unknown timezones to 'GMT' instead of throwing an exception, so we must check for this... // if (!canonicalTimezone.equalsIgnoreCase("GMT") && this.serverTimezoneTZ.getID().equals("GMT")) { throw SQLError.createSQLException("No timezone mapping entry for '" + canonicalTimezone + "'", SQLError.SQL_STATE_ILLEGAL_ARGUMENT, getExceptionInterceptor()); }
SELECT @@GLOBAL.time_zone, @@SESSION.time_zone; # @@GLOBAL.time_zone @@SESSION.time_zone # SYSTEM SYSTEM
show variables like '%time_zone%'; # Variable_name Value # system_time_zone CST # time_zone SYSTEM
CST 是个坑,安装的 Mysql 查看系统时区,显示 CST, 其实是东八区 UTC+8, 可以通过改变会话时区查看 TIMESTAMP 列的值进行验证,但是在 Java 中,CST 指的就是 Central Standard Time, 是 UTC-6, 所以如果客户端,如 Java 程序默认的时区就是 Asia/Shanghai (UTC+8), 不指定任何时区转换设置,操作和显示没有什么问题;Mysql 系统时区变量为 CST, Mysql Server 默认全局时区(System Time Zone - 全局 time_zone 变量) 为 SYSTEM , 继承自系统时区,会话时区默认(Session Time Zone - 局部 time_zone 变量)继承全局时区,最终其实就是 UTC+8。
所以如果真的存在不同客户端时区问题,必要时修改 Mysql 的系统时区为含义明确的时区表示,而不是 CST, 客户端在使用的时候也不用指定 useLegacyDatetimeCode=true&useTimezone=true&serverTimezone=时区, 使用新的 useLegacyDatetimeCode=false 获取时区的方式就可以了,这种会查询 Mysql Server 的时区变量,作为 Server 的时区,因为会话默认也是取的系统时区,所以是一致的,没有什么问题。这时候会将正确的时间转换为客户端时区的时间。
TIMESTAMP 操作真的是很麻烦了,必要时可以采用 廖雪峰-如何正确的处理时间 中策略,存储成 long 型的时间偏移量就好多了,需要比较的话,直接比较的是整数,显示时,再指定特定时区,就可以了。
Note that this wildcarding is specific to the use of resource paths in application context constructors (or when you use the PathMatcher utility class hierarchy directly) and is resolved at construction time. It has nothing to do with the Resource type itself. You cannot use the classpath*: prefix to construct an actual Resource, as a resource points to just one resource at a time.
This special prefix specifies that all classpath resources that match the given name must be obtained (internally, this essentially happens through a call to ClassLoader.getResources(…)) and then merged to form the final application context definition.
Note that classpath*:, when combined with Ant-style patterns, only works reliably with at least one root directory before the pattern starts, unless the actual target files reside in the file system. This means that a pattern such as classpath*:*.xml might not retrieve files from the root of jar files but rather only from the root of expanded directories.
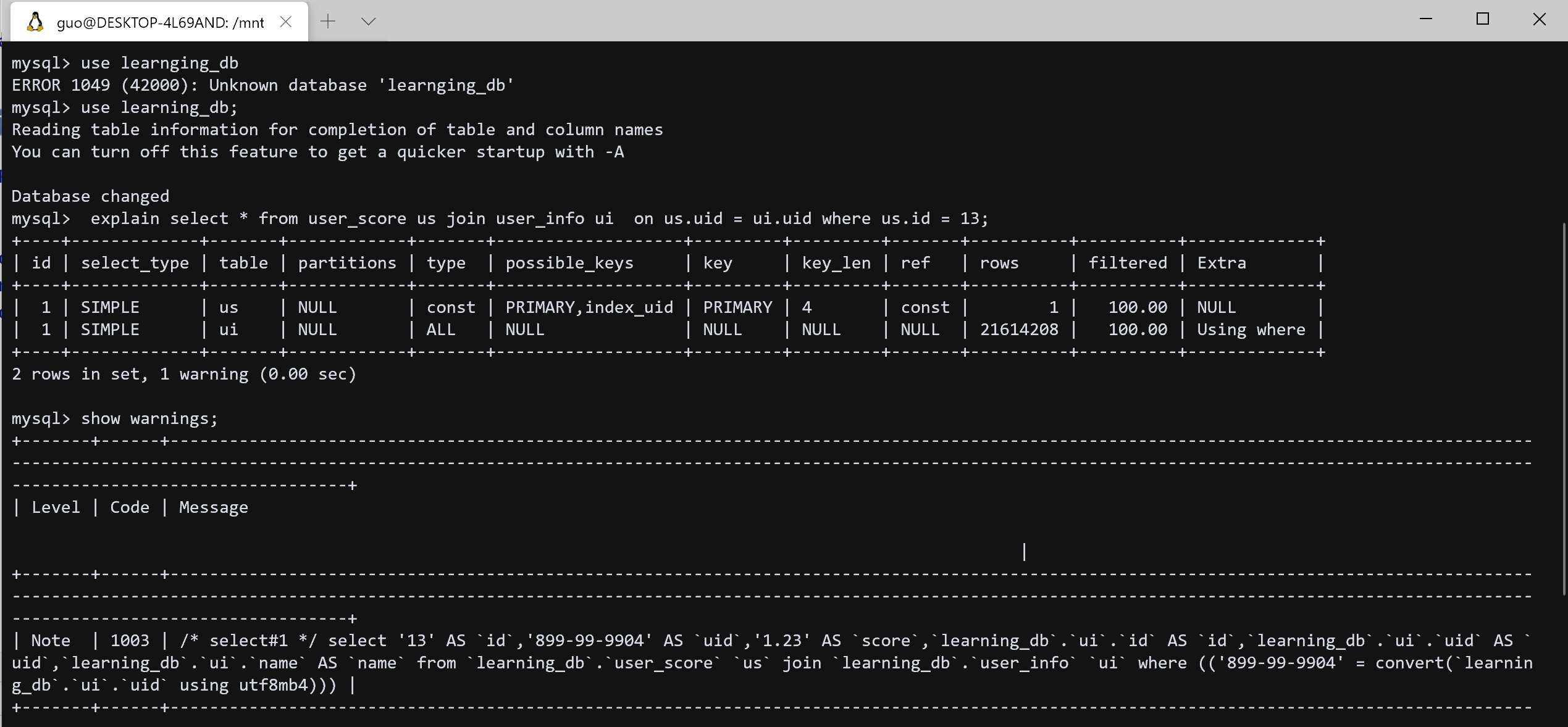
其中并没有出现 left join , 而是被转换成了 join, 大概想下, 这时的外连接其实是等价于内连接的, 如果 B 的常量等值条件要满足, B 表对应的那一行必然和 A 表中的某一行关联的上, 不能关联上, 则都为 NULL (前提是 B 的条件列声明为 NOT NULL), 所以是等价于内连接的.
因此, 在这种情况下, 写成内连接更能表达清楚本来的意图.
Mysql 手册 - 8.2.1.8 Outer Join Optimization 中的相关描述:
For a LEFT JOIN, if the WHERE condition is always false for the generated NULL row, the LEFT JOIN is changed to an inner join.
如果 t2.column 为 null, t2.column2=5 这个条件总是 false
1
SELECT * FROM t1 LEFTJOIN t2 ON (column1) WHERE t2.column2=5;
因此,可以安全的等价为一个内连接:
1
SELECT * FROM t1, t2 WHERE t2.column2=5AND t1.column1=t2.column1;
所以如果 B 的条件列可以是 NULL (没有声明为 NOT NUll), 而且条件为 B.col is NULL , 这时, 就不能等价于内连接了, 因为满足 B.col is NULL 的情况有两种, 一种是本来就没有关联上, 另一种是关联上了, 这一列的值本来就是 NULL, 就不满足 WHERE condition is always false for the generated NULL row
外连接的简化
解析阶段,右连接会被转换为只包含左连接
1
(T1, ...) RIGHT JOIN (T2, ...) ON P(T1, ..., T2, ...)
1
(T2, ...) LEFT JOIN (T1, ...) ON P(T1, ..., T2, ...)
1
select * from user_info_temp a rightjoin user_score_temp b on a.uid = b.uid;
MySQL converts the query to a query with no outer join operation if the WHERE condition is null-rejected.
A condition is said to be null-rejected for an outer join operation if it evaluates to FALSE or UNKNOWN for any NULL-complemented row generated for the operation.
如果对于外连接操作的补足NULL行(A LEFT JOIN B –> B.COL IS ALL NULL), 这些条件总是 FALSE 或者 UNKNOW 的,这些条件就是 null-rejected 的
考虑这样一个简单的外连接:
1 2 3 4 5 6 7 8 9 10 11 12
T1 LEFT JOIN T2 ON T1.A=T2.A
-- null-rejected conditions: false for `null` rows T2.B IS NOT NULL T2.B > 3 T2.C <= T1.C T2.B < 2 OR T2.C > 1
-- not null-rejected conditions: mignt be true for `null` rows T2.B IS NULL T1.B < 3 OR T2.B IS NOT NULL T1.B < 3 OR T2.B > 3
Mysql 查询优化器的工作是一个很复杂的工作流程、会考虑各种因素,参考表的统计信息,给出当前较优的执行计划。
Using filesort (JSON property: using_filesort) MySQL must do an extra pass to find out how to retrieve the rows in sorted order. The sort is done by going through all rows according to the join type and storing the sort key and pointer to the row for all rows that match the WHERE clause. The keys then are sorted and the rows are retrieved in sorted order. See Section 8.2.1.14, “ORDER BY Optimization”.