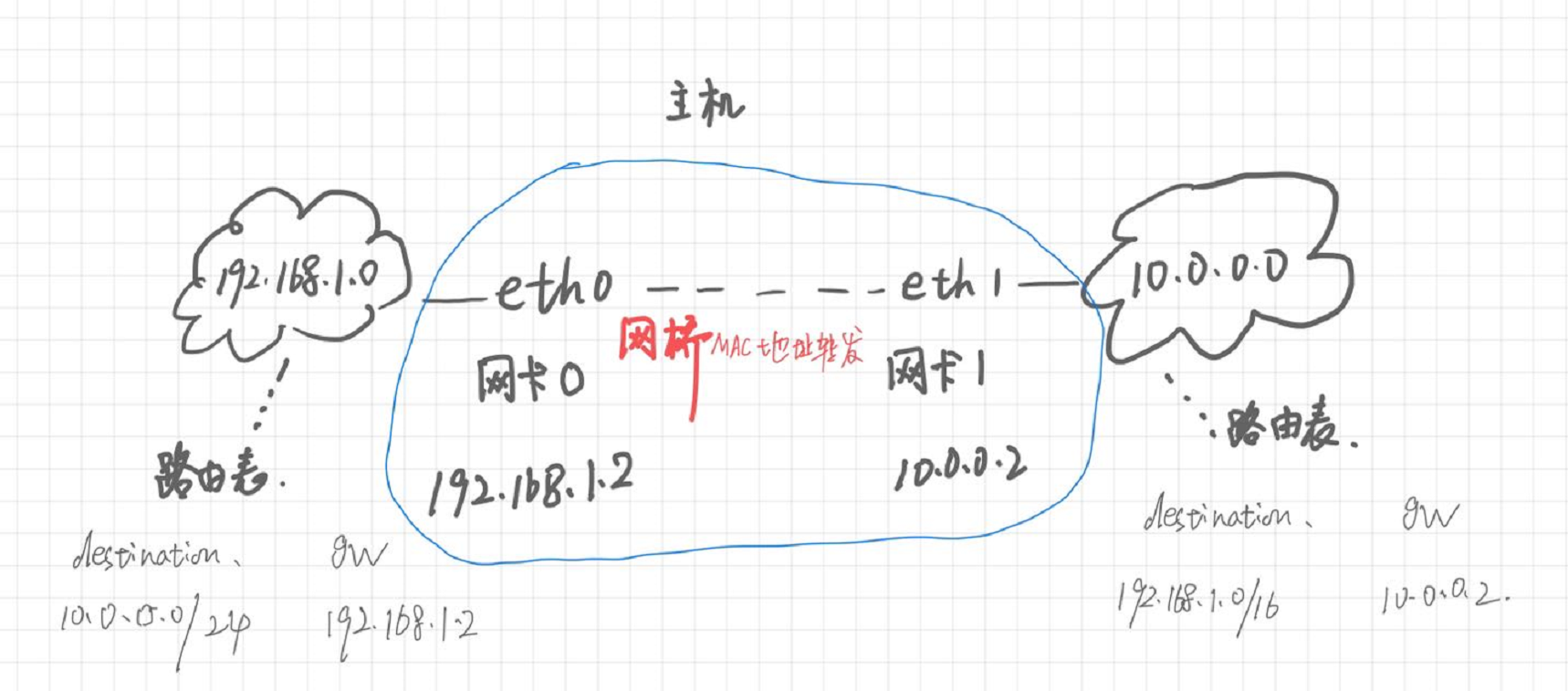
基础 Redis 事务
有时,需要在同一时间操作多个数据结构,这就需要进行多次 Redis 命令调用。虽然存在一些命令能够在 key 之间移动元素,但是并没有一个命令能够在不同类型的 key 之间移动元素(例外就是通过 ZUNIONSTORE 敏玲 复制一个 SET 到 ZSET)。对于涉及多个 key 的操作(无论是相同类型还是不同类型),Redis 提供了 5 个命令对多个 key 进行操作,且不需要中断:WATCH, MULTI,EXEC, UNWATCH, DISCARD.
Redis 最简单的事务就是使用 MULTI 和 EXEC 命令, 基础事务就意味着这两种命令提供了一种方式,使得一个客户端执行多个命令 A, B, C 时,不会被其它客户端打断,意思就是如果没有这种事务保证,A, B, C 命令一条一条执行时,执行完 A 命令,有可能其它客户端执行了 D 命令,然后这个客户端才去执行 B, A, B, C 的执行被打断了。这与关系数据库的事务时不同的,关系数据库的事务可以部分执行,然后回滚或是提交。在 Redis 中,作为 MULTI/EXEC 事务中一部分的每一个命令都是一个接一个执行的,直到所有命令全部完成,然后其它客户端才能执行它们的命令.
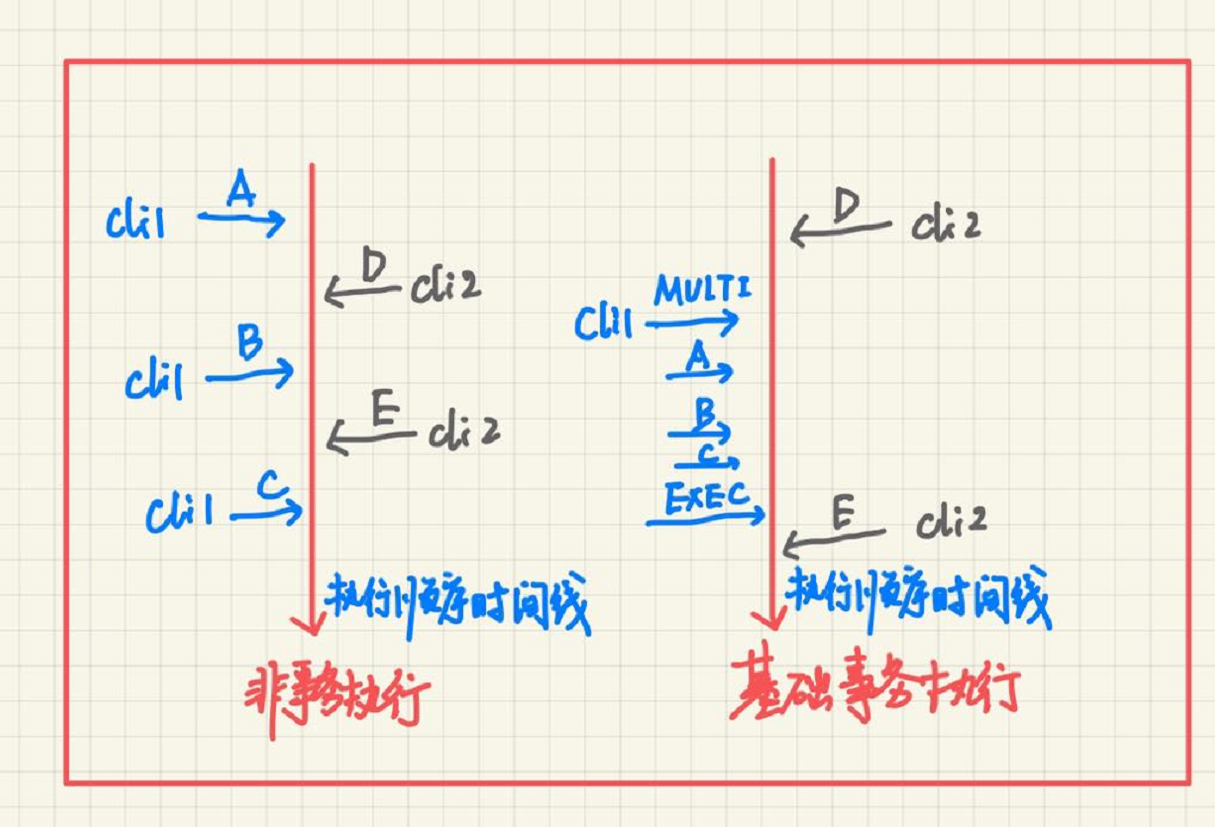
要在 Redis 中之执行一个事务的步骤:
- 首先调用
MULTI命令 - 跟随一系列要执行的其它命令, Redis 会将该连接到来的这些命令存在队列中
- 执行
EXEC命令, Redis 会顺序地执行 2 步骤中地所有命令,并且不会被中断
语义上, Redis 的 Python 客户端库使用一种称之为管道 popeline 的方式处理这种事务,在一个连接对象上调用 pipeline() 方法会创建一个事务,使用正确的话, 会自动将一系列命令列封装在 MULTI 和 EXEC命令之间, 于此同时, Python 的客户端也会将要发送的命令存储起来,直到真正要送的时候, 才发送这些命令. 这能够减少 Redis 服务器与客户端的网络通信次数, 能够提高命令的执行效率, 提高性能.
如何验证 ? 可以通过多线程验证, 每个线程都是先对某个计数器 key 加 1, 再减 1, 非事务的情况下, 一个线程的 +1 和 -1 操作可能被其它 线程的 +1 和 -1 操作打断; 如果使用了 Redis 事务, 则不会出现这种情况。
其它客户端也是如此 ?
使用事务的好处和坏处是什么?
Redis 事务
MULTI/EXEC 这种基础事务的问题在于,如果没有执行 EXEC 命令,那么之前的任何命令都不会被执行, 这意味着不能利用中间一些读操作的结果来在程序中及时做出决策。
WATCH 命令结合 MULTI 和 EXEC 命令, 以及 UNWATCH 和 DISCARD 命令,当通过 WATCH 命令关注 (watch) 键时,在执行 EXEC 操作前的任意时刻,这些键被其它客户端替换、更新或删除,那么这时尝试执行 EXEC 会失败,并返回错误信息。通过使用 WATCH, MULTI/EXEC, 以及 UNWATCH/DISCARD 命令可以确保在做一些重要的操作时,数据不会被修改。
UNWATCH/DISCARD 的区别
1 | WATCH |
如果通过 WATCH 命令关注了一些 key, 然后通过 MULTI 命令开启了一个事务,并跟随了一组命令,这时可以通过 DISCARD 命令取消关注,并清除任何缓存的命令。
客户端1操作
1 | 127.0.0.1:6379> get guoph2 |
客户端2操作
1 | 127.0.0.1:6379> get guoph2 |
结合 WATCH 与 MULTI/EXEC 命令,就可以在关注的键被其它客户端修改时得到通知,可以再次进行重试。
为什么 Redis 不实现典型的锁机制
当处于写数据的目的而访问数据时,即 SQL 中的 SELECT FOR UPDATE, 关系型数据库会对要访问的行进行加锁,直到一个事务通过 COMMIT 或者 ROLLBACK完成事务的处理. 如果其它客户端尝试对相同的行,access data for writing 时,其它客户端会被阻塞直到第一个事务完成。这种形式的锁在实际中应用的很好(特别是所有的关系型数据库都实现了它),但是可能会导致客户端等待获取锁而长时间等到锁。
由于这种可能存在的长时间等待,并且 Redis 的设计就是较少客户端的等待时间,Redis 在 WATCH期间并不会锁数据,相反,Redis 会通知客户端,如果其它客户端先修改了数据,这也被称之为乐观锁 (optimistic locking). 关系型数据库执行的锁可以被视作悲观锁 (pessimistic). 乐观锁同样也应用广泛,因为客户端从来不等待第一个锁的持有者释放锁,它只是在不断地进行重试。